
If we declare an array of size 3. As we know that all the values of an array are stored in a continous manner, so all the three values of an array are atored in a sequential fashion. Then, total memory space occupied by array would is 3*4=12 bytes.
-We cannot insert more than three elements in above example beacuse only 3 spaces are allocated by 3 elements.
-In case of array, the wastage of money can occur.
-In array, we are providing fixed-size at compile time,due to which wastage of memory occurs. The solution of this problem is to use linked list.
A linked list is also a collection of elements, but the elements are not stored in a consecutive location. or linked list is a collection of the nodes in which one node is connected to another node and node consists of two parts i.e,one is data part and second one is the address part.
In linked ,list one is variable and the second one is pointer variable. we can declare linked list by using user- defined data type called as structure.
struct node
{
int data;
struct node*next;
}
1- Singly linked list:- the singly linked list is the most common which consists of data part and address part. The address part in the node is known as a pointer. example:- suppose we have four nodes and addresses of the four nodes are 100,200,300,400.
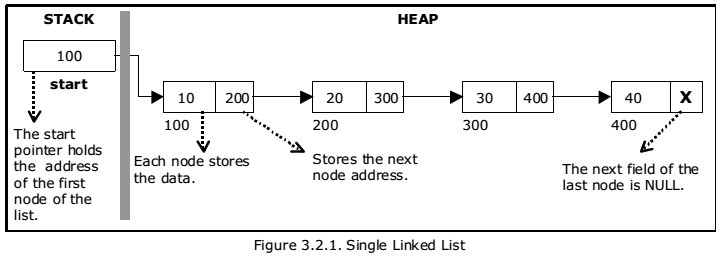
NULL means its address part does not point to any node. the pointer that holds the address of the initial node is known as a head pointer.
2-Doubly linked list:As name suggests, the doubly linked list contains two pointers. We define it in three parts the data part and the two address part.
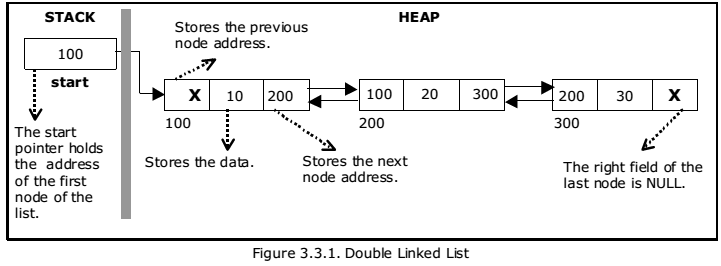
Representation of doubly linked list:-
struct node
{
int data;
struct mode*next;
struct node*prev;
}
3- Circular linked list:- A circular linked list is a variation of a singly linked list the only difference is "last node does not point to any node in a singly linked list".
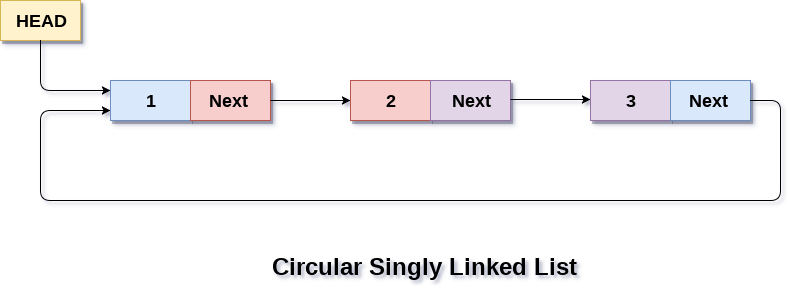
Representation of circular linked list:-
struct node
{
int data;
struct node*next;
}
4-Doubly circular linked list:-The doubly circular linked list has the features of both the circular linked list and doubly linked list.
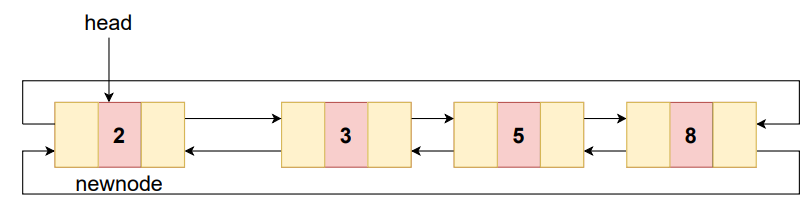
The last node is attached to the first node and thus creates a circle. The main difference is that doubly circular linked list does not contain NULL value in previous field of the node.
Representation of doubly linked list:-
struct node
{
int data
struct node*next;
struct node*prev;
| Singly linked list | Average Acess-Q(n) search-Q(n) insertion-Q(1) deletion-Q(1) |
Space complexity Worst O(n) |
||
|---|---|---|---|---|
| Singly linked list | Worst Access-O(n) Search-O(n) Insertion-O(1) Deletion- O(1) |
1-Node creation:-
struct node
{
int data;
struct node*next;
};
struct node*head,*ptr;
ptr=(struct node*)malloc(size of (struct node*))
2-Insertion:-
1-Insertion at beginning:- It involves inserting any
element at the front of the list. We just need a few link adjustment to make new node as head of list.
2. Insertion at end of list:- The new node can be inserted as the only node in the list / it can be inserted as last one.
3-Insertion after specified node :- We need to skip desired number of nodes in order to reach node after which the new node will be inserted.
3-Deletion and Traversing:-
1.Deletion at beginning:-It just needs few adjustments in the node pointers.
2-Deletion at end of list :- The list can either be empty or full. Different logic is implemented for different scenario's.
Traversing :- In traversing, we simply visit each node & the list at least once in order to perform some specific operation in it, for example, printing data part of each node present in the list.
Searching :- In searching, we match each element of the list with the given element.If the element is found on any of the location of that element is returned otherwise null is returned.
1-Node creation:-
struct node
{
struct node*prev;
int data;
struct node*next;;
};
struct node*head;
2-Insertion:-
1-Insertion at the beginning:-Adding the node into the liked list at the beginning.
2-Insertion at end:- Adding the node into the linked list to the end.
3-Deletion and traversing:-
1-Deletion at beginning :- Removing the node from beginning of the list.
2-Deletion at end :- Removing the node from end of the list.
Traversing :-Visting each node of the list at least once in order to perform some specific operation like searching, sorting, display etc.
Searching:-Compilining each node data with the item to be searched and return location of the item in the list if the item found else return null.
What is a skip list?
A skip list is a probalistic data structure.The skip list is used to store a linked list of elements or data with a inked list. In one single step, it skips several elements of the entire list which is why it is known as skip list.
Structure of skip list:-
Skip list is built in two layers: The lowest layer & and the top layer. The lowest layer of the skip list is a common sorted linked list, and the top layers of the skip list are the like an "express line where elements are skipped.
| S.no | Complexity | Average Case | Worst Case |
|---|---|---|---|
| 1 | Access Complexity | o(log n) | o(n) |
| 2 | Search Complexity | o(log n) | o(n) |
| 3 | Delete Complexity | o(log n) | o(n) |
| 4 | Insert Complexity | o(log n) | o(n) |
| 5 | Space Complexity | - | o(nlogn) |
Insertion operation :- It is used to add new node a particular location in a specific situation.
Deletion operation :- It is used to delete a node in a specific situation.
search operation :- The search operation is used to search a particular node in a skip list.
Insertion (L, key)
local update [0...max-level+1]
a = L -> header
for i = L -> level down to a
while a -> forward [i]→ key forward [i]
update[i]=a
a = a + forward[a]
|V| = random-level()
if |V| > L -> level then
fOR i = L -> Level + 1 to |V| do
update [i]=L -> header
L -> level = |V|
a = make node (|V|, key, value)
for i = 0 to level do
a → Forward [i] = update[i] -> forward (i)
update [i] -> forward [i]= a
Deletion (L, key)
local update (o... max-level + 1]
a = L+ header
for i=L -> level downs 0 to ao
while a -> forward [i] → key forward [i]
update [i]=a
a = a -> forward [0]
if a -> key = key then
for i=0 to L -> level do
if update [i] -> forward [i] & a then break
update [i] -> forward [i] → forward [i]
free (a)
while L -> level > 0 and 1 ->header ->Forword[L-> level] = NIL do
L -> level = L -> level-1
Searching (L, SKey)
a = L → header
loop invariant: a → key level down to 0 do.
while a → forward[i] → key forward[i]
a = a → forward[0]
if a → key = SKey then return a → value
else return failure
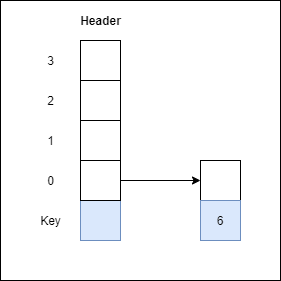
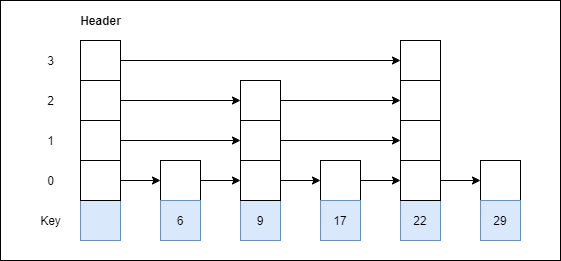
Example 1: Create a skip list, we want to insert these following keys in the empty skip list
1. 6 with level 1.
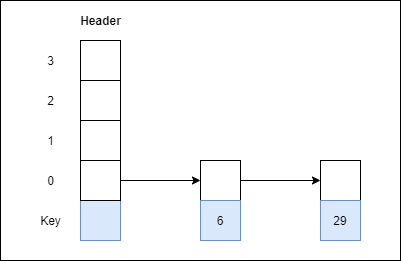
2. 29 with level 1.
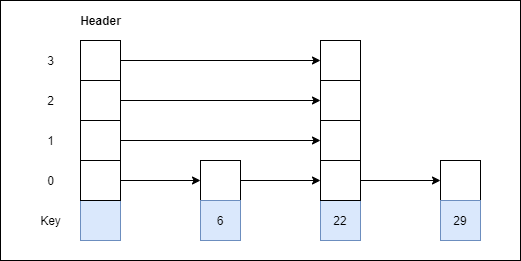
3. 22 with level 4.
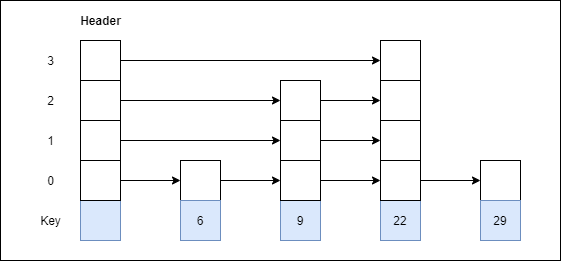
4. 9 with level 3.
5. 17 with level 1.
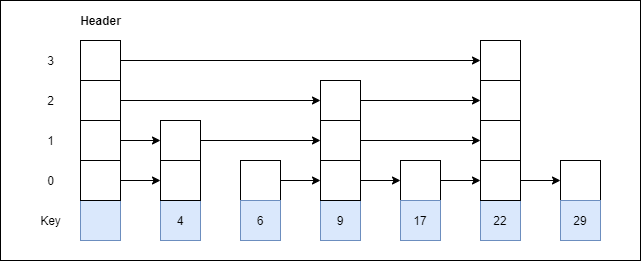
6. 4 with level 2.
Ans:
Step 1: Insert 6 with level 1
Step 2: Insert 29 with level 1
Step 3: Insert 22 with level 4
Step 4: Insert 9 with level 3
Step 5: Insert 17 with level 1
Step 6: Insert 4 with level 2
| Sr.No | Complexity | Average case | Worst case |
|---|---|---|---|
| 1- 2- 3- 4- 5- |
Access complexity Search complexity Delete complexity Insert complexity Space complexity |
O(log n) O(log n) O(log n) O(log n) - |
O(n) O(n) O(n) O(n) O(n log n) |
Basic operations and its algorithms:-
1-Insertion operation:- It is used to add new node to particular location in a specific situation.
2-Deletion operation:- It is used to delete a node in a soecific situation.
3-Search operation:- The search operation is used to search a particular node in a skip list.
Algorithm of insertion operation:-
Insertion (L,Key)
local update[0---- mean -level+1]
a=L-->header
for i=L --> level down to a do
while a--> Forward[i]-->Key forward[i]
update [i]=a